

OpenAI is ensuring an additional layer of oversight by establishing a “cross-functional Safety Advisory Group” above the technical teams
In a move to bolster its defenses against the potential threats posed by harmful AI, OpenAI is expanding its internal safety protocols. A newly established “safety advisory group” will now sit above technical teams, providing recommendations to leadership. Moreover, the board has been endowed with veto power, though the actual exercise of this authority remains uncertain.
Typically, the intricacies of such policies remain confined to closed-door meetings, obscured by functions and responsibilities understood by only a select few. However, given recent leadership changes and the evolving discourse on AI risks, it’s worth delving into how the world’s leading AI development company is approaching safety considerations.
OpenAI has outlined its updated “Preparedness Framework” in a recent document and blog post. This framework, presumably refined after the November shake-up that saw the departure of two “decelerationist” board members, Ilya Sutskever and Helen Toner, aims to provide a clear pathway for identifying, analyzing, and addressing “catastrophic” risks associated with their developing models.
The term “catastrophic risk” is defined as any risk capable of causing hundreds of billions of dollars in economic damage or resulting in severe harm or death to many individuals, encompassing existential risks like the feared “rise of the machines.”
Models in production fall under the purview of a “safety systems” team, responsible for addressing systematic abuses. Frontier models in development are overseen by the “preparedness” team, focusing on risk identification and quantification before model release. Additionally, the “superalignment” team works on theoretical guide rails for potentially “superintelligent” models.
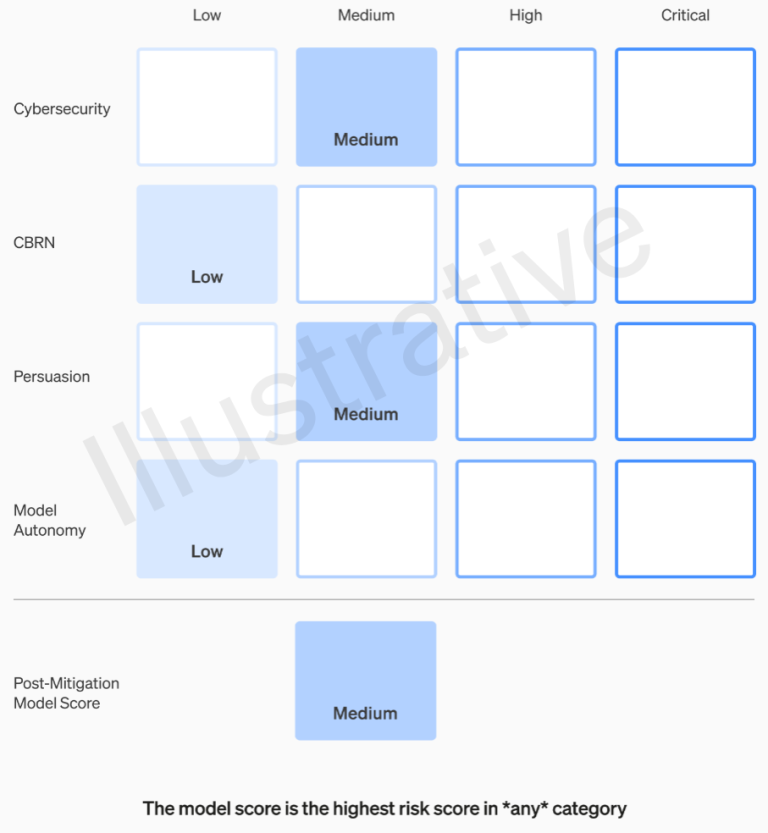
The first two categories deal with real-world risks and have a straightforward rubric. Models are assessed on four risk categories: cybersecurity, persuasion (e.g., disinformation), model autonomy, and CBRN threats (chemical, biological, radiological, and nuclear threats). Mitigations are considered, and if a model is deemed to have a “high” risk after accounting for known mitigations, it cannot be deployed. Models with any “critical” risks are halted from further development.
The risk levels and their criteria are documented in the framework, eliminating ambiguity and leaving no room for individual discretion. For instance, the cybersecurity section defines risks from “medium” (increasing productivity) to “critical” (model devising and executing novel cyberattack strategies).
OpenAI is ensuring an additional layer of oversight by establishing a “cross-functional Safety Advisory Group” above the technical teams. This group will review reports from technical experts and provide recommendations from a higher vantage point, potentially uncovering “unknown unknowns.” These recommendations will be simultaneously shared with the board and leadership, allowing for a comprehensive decision-making process. While leadership retains the final say on deployment, the board has the authority to reverse these decisions.
This proactive approach underscores OpenAI’s commitment to responsible AI development and its recognition of the need for multi-layered safety measures in the rapidly advancing field of artificial intelligence.






